
CBC翻转攻击
加密与解密
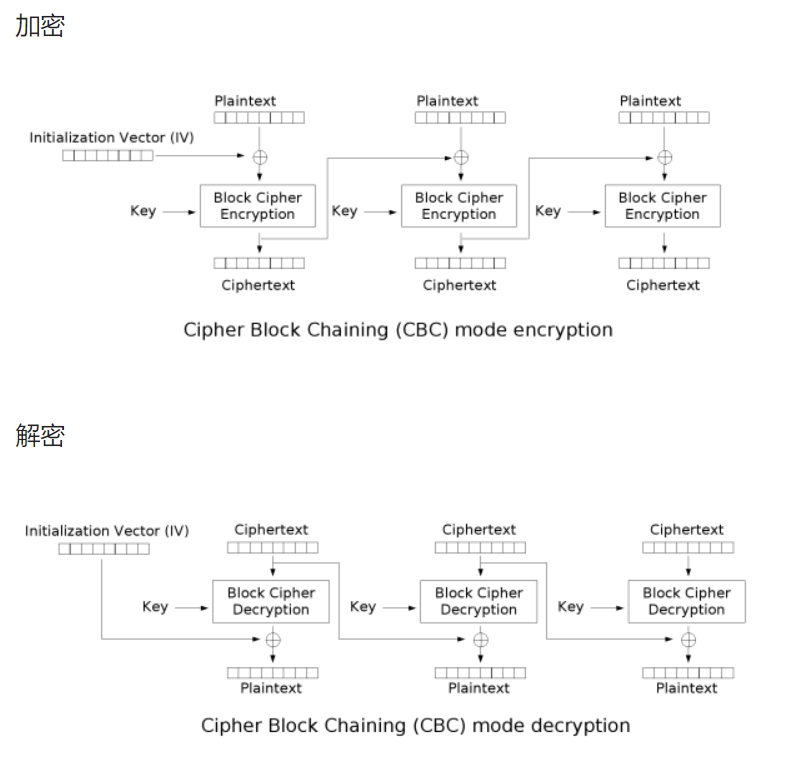
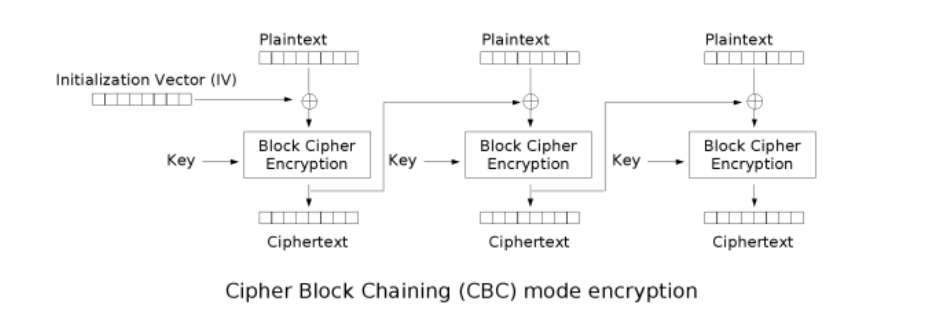
Plaintext:明文数据
IV:初始向量
Key:分组加密使用的密钥
Ciphertext:密文数据
明文都是先与混淆数据(第一组是与IV,之后都是与前一组的密文)进行异或,再执行分组加密的。
分组加密算法在实现加解/密时,需要把消息进行分组(block),而block的大小常见有64bit、128bit、256bit等。
对于CBC,整个加密的过程简单说来就是:
1.首先将明文分组(常见的以16字节为一组),位数不足的使用特殊字符填充(padding)。
2.生成一个随机的初始化向量(IV)和一个密钥。
3.将IV和第一组明文异或。
4.用密钥对3中xor后产生的密文加密。
5.用4中产生的密文对第二组明文进行xor操作。
6.用密钥对5中产生的密文加密。
7.重复4-7,到最后一组明文。
8.将IV和加密后的密文拼接在一起,得到最终的密文。
以下引用自白帽子讲web安全
介绍一下padding,以8个字节的block为例:
比如明文是FIG,长度为3个字节,则剩下5个字节被填充了0x05,0x05,0x05,0x05,0x05这5个相同的字节,每个字节的值要等于需要填充的字节长度。如果明文长度刚好位8个字节,如:PLANTAIN,则后面需要填充8个字节的padding,其值为0x08。这种填充方法,遵循的是最常见的PKCS#5标准。
而对于解密过程,前一块密文参与下一块密文的还原:
1.从密文中提取出IV,然后将密文分组。
2.使用密钥对第一组的密文解密,然后和IV进行xor得到明文。
3.使用密钥对第二组密文解密,然后和2中的密文xor得到明文。
4.重复2-3,直到最后一组密文。
攻击原理
下面是进行CBC翻转攻击的原理图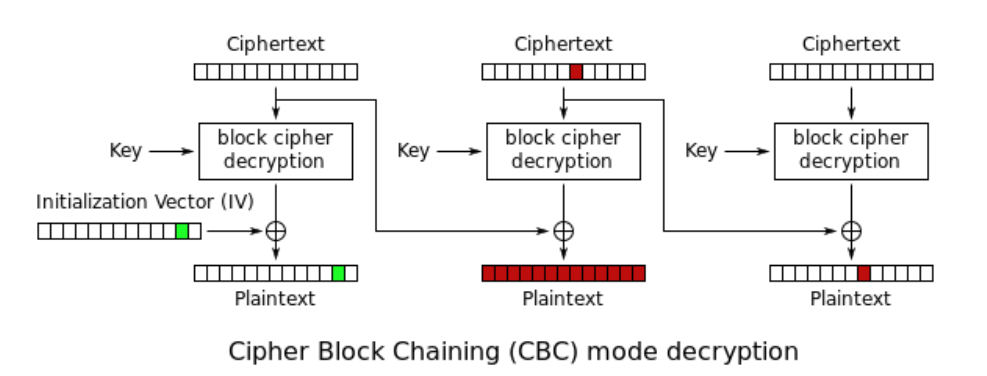
可以注意到,前一块Ciphertext用来产生下一块明文,如果我们改变前一块Ciphertext中的一个字节,然后和下一块解密后的密文xor,就可以得到一个不同的明文,而这个明文是我们可以控制的。利用这一点,我们就欺骗服务端或者绕过过滤器。
同样的需要看到,修改了Ciphertext中的一个字节,对应该block解密出来的明文就完全不同了。
接下来就是我这个菜狗当时理解半天的东西了,怎么翻转攻击生成我们想要的明文: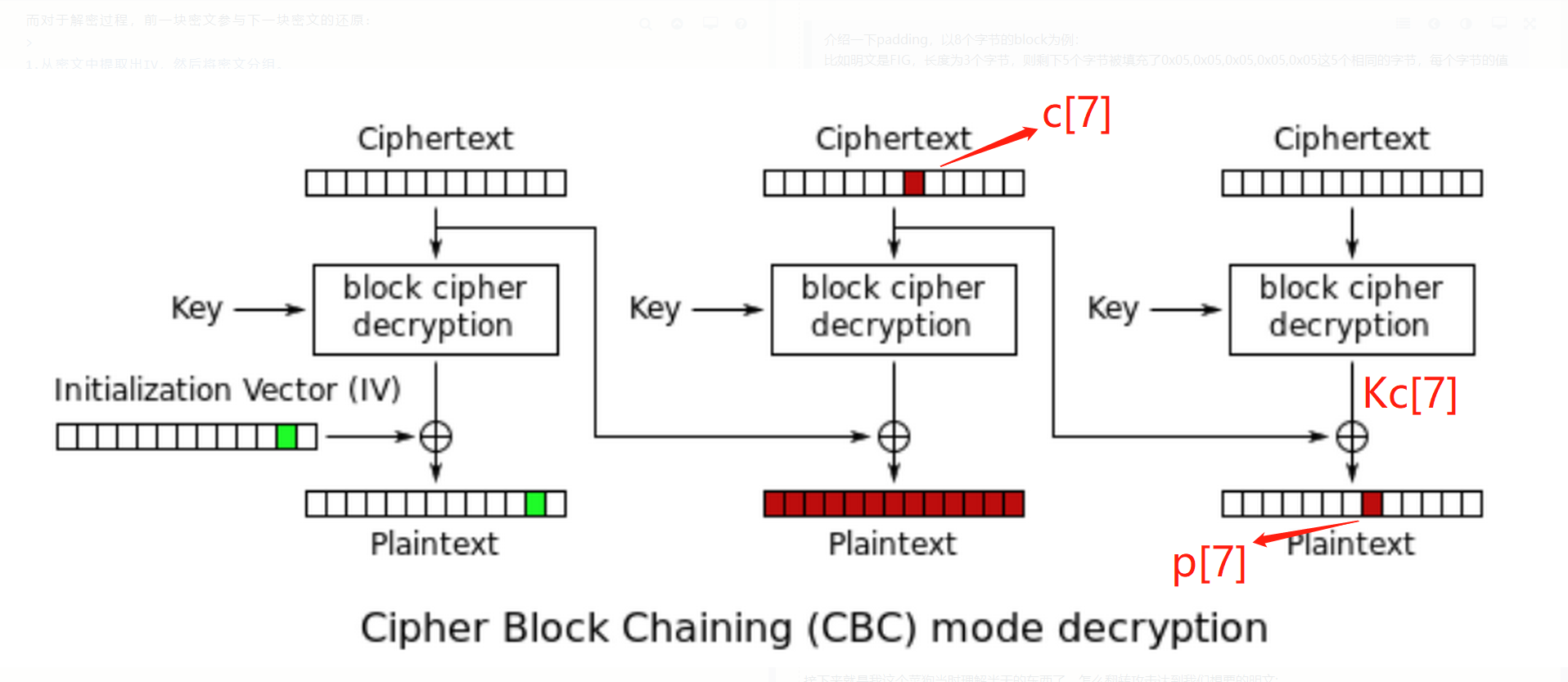
假如此时明文p[7]显示“g”,我们想要让它变成“G”
我们知道: c[7]^Kc[7]=p[7] 即c[7]^p[7]=Kc[7]
也即c[7]^ ord(‘g’)=Kc[7]
若让p’[7]字符为“G”,就要推算出新的c’[7]
在这个过程中Kc[7]始终不变
所以c’[7]=Kc[7]^p’[7]=c[7]^ ord(‘g’)^ord(‘G’)
到此将密文c[7]的值修改为c’[7]就完成了CBC翻转
如果想要修改第一组明文,我们就要对IV值进行翻转,也是同理。
如果想要整段明文修改1
2for i in range(0,len(iv)):
bin_iv[i] = bin_iv[i] ^ bin_p[i] ^ ord('X')
可以看到在不知道key的情况下,通过修改密文和IV(还有个条件是获得每次解密后的结果 ),可以控制输出的明文为自己想要的内容,而且只能从最后一组开始修改,并且每改完一组,都需要重新获取一次解密后的数据,要根据解密后的数据来修改前一组密文的值(如果想要保持整体明文只有关键地方有变化)。
Padding Oracle Attack(POA)
参考《白帽子讲Web安全》11.5节内容,根据padding规则,CBC字节翻转攻击和解密结果是否合规的不同状态来进行明文的猜解。以及https://www.freebuf.com/articles/system/163756.html
padding
先提一下padding,实际加密数据时,由于明文长度不会一直正好是分组的倍数,因此就需要添加附加的数据来使得加密的数据的长度是分组长度的倍数。
使用以下策略添加(按照AES算法):
如果需要添加一个字节,就添加0×01
如果需要添加两个字节,就添加0×02 0×02
三个字节就是:0×03 0×03 0×03,依次类推。
如果正好是分组长度倍数,如16个字节,也需要再添加16个0×16进行padding
攻击原理
这里有几个概念要先理清一下:
基于密码学算法的攻击,往往第一个要搞清楚的是,我们在攻击谁,或者准确的说我们的攻击点在哪里?在一个密码学算法中,有很多的参数(指攻击者可以控制的参数),攻击者往往是针对其中某一个或某一些参数进行破解,穷举等攻击。在Padding Oracle Attack攻击中,攻击者输入的参数是IV+Cipher,我们要通过对IV的”穷举”来请求服务器端对我们指定的Cipher进行解密,并对返回的结果进行判断。
和SQL注入中的Blind Inject思想类似。我觉得Padding Oracle Attack也是利用了这个二值逻辑的推理原理,或者说这是一种”边信道攻击(Side channel attack)”。http://en.wikipedia.org/wiki/Side_channel_attack
这种漏洞不能算是密码学算法本身的漏洞,但是当这种算法在实际生产环境中使用不当就会造成问题。
和盲注一样,这种二值逻辑的推理关键是要找到一个”区分点”,即能被攻击者用来区分这个的输入是否达到了目的(在这里就是寻找正确的IV)。比如在web应用中,如果Padding不正确,则应用程序很可能会返回500的错误(程序执行错误);如果Padding正确,但解密出来的内容不正确,则可能会返回200的自定义错误(这只是业务上的规定),所以,这种区别就可以成为一个二值逻辑的”注入点”。
5.攻击成立的两个重要假设前提:
- 攻击者能够获得密文(Ciphertext),以及附带在密文前面的IV(初始化向量)
- 攻击者能够触发密文的解密过程,且能够知道密文的解密结果
我们向服务器发送这样一个请求:
Request: http://sampleapp/home.jsp?UID=0000000000000000EFC2807233F9D7C097116BB33E813C5E
Respose: 500 - Internal Server Error
前面的16个字母(即8字节 ASCII十六进制表示法两个字母为一个字节)为攻击者输入的IV。后面的32个字母(即16字节)为攻击者输入的密文)
此时在解密时Padding是不正确的(填充的值和填充的数量不一致)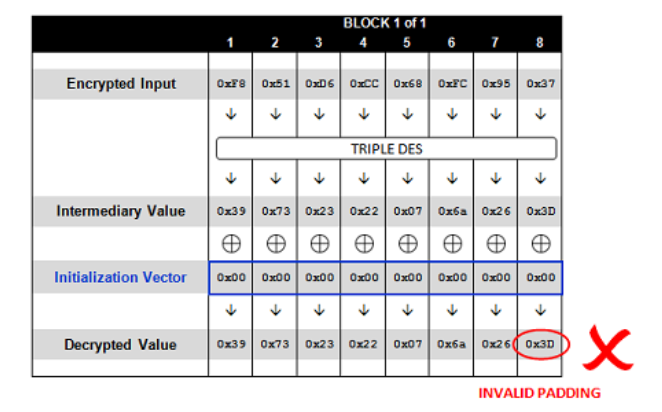
我们接下来要利用选择密文攻击的思想,不断调整,修正IV。来对Intermediary Value进行猜测。
1) Padding 0×01
我们不断地调整IV的值,以希望解密后,最后一个字节的值为正确的Padding Byte,这里是0×01。因为Intermediary Value是固定的(我们此时不知道Intermediary Value),因此从0×00~0xFF之间,只可能有一个IV的值与Intermediary Value的最后一个字节进行XOR后,结果是0×01(思考: 因为0×01只有最后1 bit为1,其他都是0,所以根据XOR的性质,只能存在一个值能XOR得到0×01)。攻击者通过遍历这255个值,可以找出IV需要的最后一个字节。
Request: http://sampleapp/home.jsp?UID=0000000000000066EFC2807233F9D7C097116BB33E813C5E
Respose: 200 OK
通过XOR运算,可以马上推导出此Intermediary Byte的值:1
2
3
4if(Inermediary Byte) ^ 0x66 == 0x01 {
Inermediary Byte = 0x66 ^ 0x01 }
so:
Inermediary Byte = 0x67

在回过头来看看加密过程:
初始化向量IV与明文进行XOR运算得到了Inermediary Value,因此将刚才得到的Inermediary Byte(0×67)与”真实”的IV的最后一个字节0x0F(攻击者事先获取到的)进行XOR运算,即能得到明文:
0x67 ^ 0x0F = 0x68 : H
在正确”匹配”了Padding 0×01之后,需要做的是继续推导出剩下的Intermediary Byte。根据Padding 原则,在需要Padding两个字节的时候,其值应该是0×02。
2) Padding 0×02
这个时候我们要注意,之前说过,这个攻击过程是个循环迭代的过程,上一步的结果就是作为下一步的基础。
我们之前已经知道Intermediary Byte的最后一个字节为0×67,因此可以”更新”IV(攻击者输入的IV)的第8个字节为 0×67 ^ 0×02 = 0×65。(对原文进行了修改)
(思考: 这个Padding Oracle Attack的过程中,攻击者需要不断地调整输入IV的值,之前因为在Padding 0×01中,我们只是在假设Padding 0×01的情况,在这个假设下,我们通过得出IV的最字节,从而计算出Intermediary Byte,进而算出明文的最后一个字节”H”。这里要注意的是,这个假设的IV没有任何意义,只是我们进行”选择密文攻击”过程中的一个路人甲而已。而接下来我们要继续假设Padding 0×02的情况,为了使在假设Padding 0×02中,Intermediary Value的最后一个字节依然为”0×67(之前算出来的)”,所以我们要对IV的最后一个字节进行迭代更新: 0×67 ^ 0×02 = 0×65 )。
这个时候,本质上攻击者是固定住了IV的最后一个字节不变,开始循环”盲注”倒数第二个字节。开始依照第一步时的方法对倒数第二个字节进行”盲注”逻辑判断,假如通过遍历可以得出,IV的第7个字节为0×70,则:
Request: http://sampleapp/home.jsp?UID=0000000000007065EFC2807233F9D7C097116BB33E813C5E
Respose: 200 OK
接下来同样地求出Intermediary Byte的倒数第二个字节,再推出明文。
以此类推,得出明文所有位。
(其实总体挺好理解的,但是我只有一个问题,比如穷举最后一位时,怎么确定解密时前一位的值是不是0x01,如果是0x01不是会报错,然后跑不出来吗?)