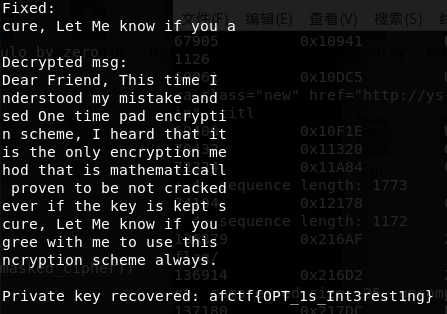
key='afctf{OPT_1s_Int3rest1ng}' c1='Dear Friend, This time I u' c2='nderstood my mistake and u' c3='sed One time pad encryptio' c4='n scheme, I heard that it ' c5='is the only encryption met' c6='hod that is mathematically' c7=' proven to be not cracked ' c8='ever if the key is kept se' c9='cure, Let Me know if you a' c10='gree with me to use this e' c11='ncryption scheme always.'
#!/usr/bin/python ## OTP - Recovering the private key from a set of messages that were encrypted w/ the same private key (Many time pad attack) - crypto100-many_time_secret @ alexctf 2017 # Original code by jwomers: https://github.com/Jwomers/many-time-pad-attack/blob/master/attack.py)
import string import collections import sets, sys
# 11 unknown ciphertexts (in hex format), all encrpyted with the same key
# XORs two string defstrxor(a, b):# xor two strings (trims the longer input) return"".join([chr(ord(x) ^ ord(y)) for (x, y) in zip(a, b)])
deftarget_fix(target_cipher): # To store the final key final_key = [None]*150 # To store the positions we know are broken known_key_positions = set()
# For each ciphertext for current_index, ciphertext in enumerate(ciphers): counter = collections.Counter() # for each other ciphertext for index, ciphertext2 in enumerate(ciphers): if current_index != index: # don't xor a ciphertext with itself for indexOfChar, char in enumerate(strxor(ciphertext.decode('hex'), ciphertext2.decode('hex'))): # Xor the two ciphertexts # If a character in the xored result is a alphanumeric character, it means there was probably a space character in one of the plaintexts (we don't know which one) if char in string.printable and char.isalpha(): counter[indexOfChar] += 1# Increment the counter at this index knownSpaceIndexes = []
# Loop through all positions where a space character was possible in the current_index cipher for ind, val in counter.items(): # If a space was found at least 7 times at this index out of the 9 possible XORS, then the space character was likely from the current_index cipher! if val >= 7: knownSpaceIndexes.append(ind) #print knownSpaceIndexes # Shows all the positions where we now know the key!
# Now Xor the current_index with spaces, and at the knownSpaceIndexes positions we get the key back! xor_with_spaces = strxor(ciphertext.decode('hex'),' '*150) for index in knownSpaceIndexes: # Store the key's value at the correct position final_key[index] = xor_with_spaces[index].encode('hex') # Record that we known the key at this position known_key_positions.add(index)
# Construct a hex key from the currently known key, adding in '00' hex chars where we do not know (to make a complete hex string) final_key_hex = ''.join([val if val isnotNoneelse'00'for val in final_key]) # Xor the currently known key with the target cipher output = strxor(target_cipher.decode('hex'),final_key_hex.decode('hex'))
print"Fix this sentence:" print''.join([char if index in known_key_positions else'*'for index, char in enumerate(output)])+"\n"
# WAIT.. MANUAL STEP HERE # This output are printing a * if that character is not known yet # fix the missing characters like this: "Let*M**k*ow if *o{*a" = "cure, Let Me know if you a" # if is too hard, change the target_cipher to another one and try again # and we have our key to fix the entire text!
#sys.exit(0) #comment and continue if u got a good key
target_plaintext = "cure, Let Me know if you a" print"Fixed:" print target_plaintext+"\n"
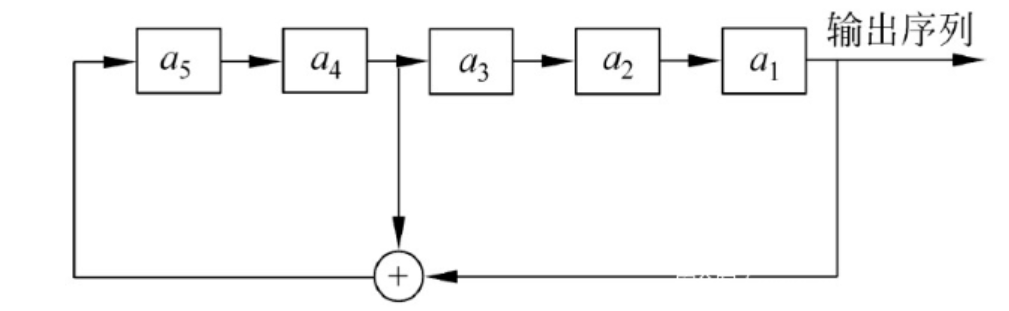
f=open("key","w") for i in range(100): tmp=0 for j in range(8): (R,out)=lfsr(R,mask) tmp=(tmp << 1)^out f.write(chr(tmp)) f.close()
key文件转换成16进制字符串:
1 2 3 4
with open('key', 'r') as f: print f.read().encode('hex') #20FDEEF8A4C9F4083F331DA8238AE5ED083DF0CB0E7A83355696345DF44D7C186C1F459BCE135F1DB6C76775D5DCBAB7A783E48A203C19CA25C22F60AE62B37DE8E40578E3A7787EB429730D95C9E1944288EB3E2E747D8216A4785507A137B413CD690C #转成二进制
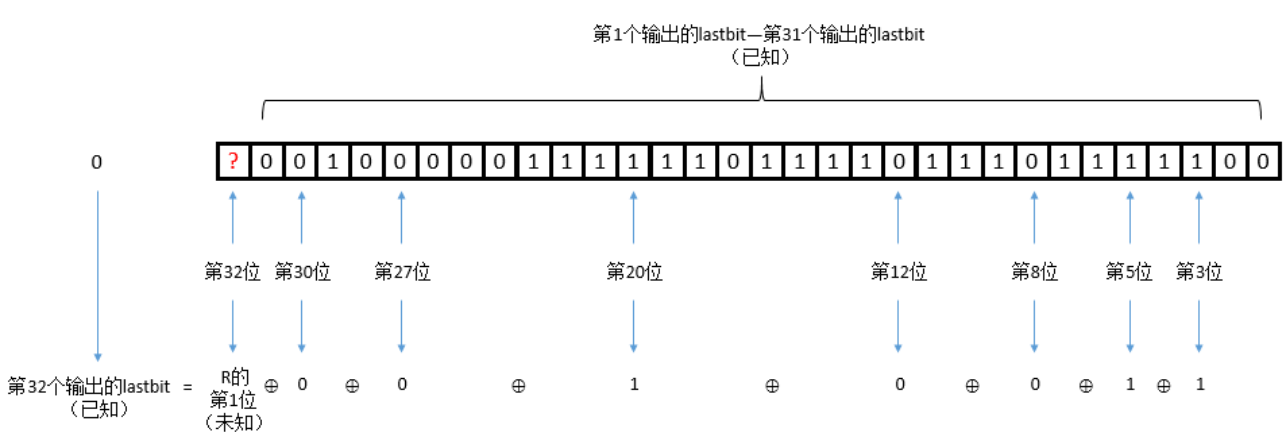
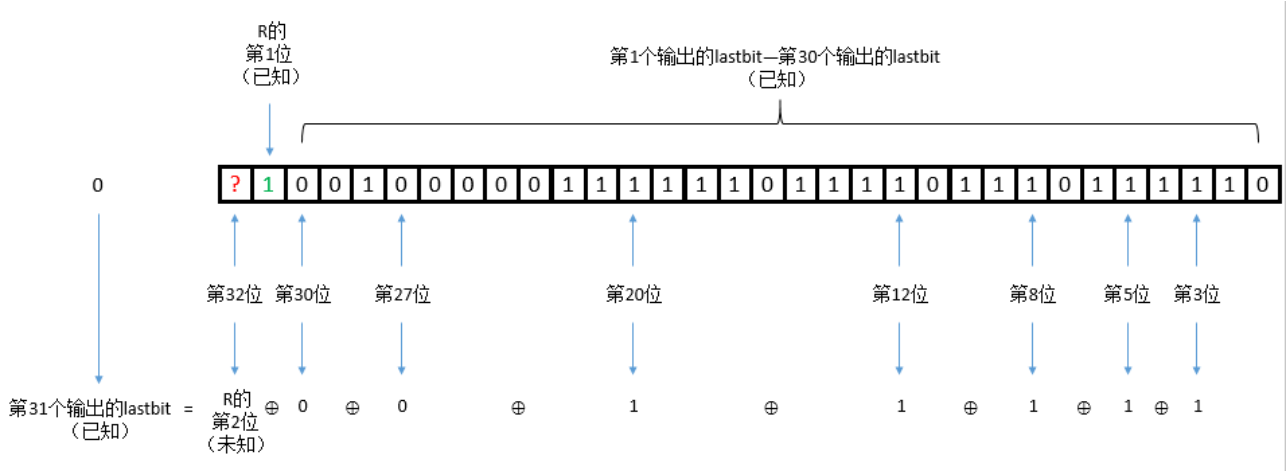
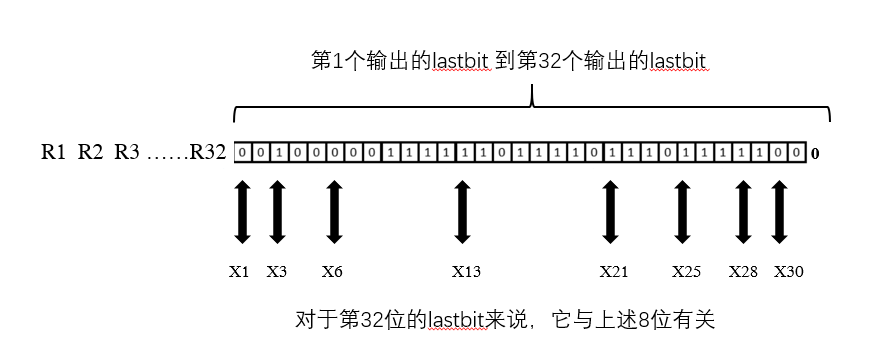
R = '' for i in range(32): output = '?' + key[:31] ans = int(tmp[-1-i])^int(output[-3])^int(output[-5])^int(output[-8])^int(output[-12])^int(output[-20])^int(output[-27])^int(output[-30]) R += str(ans) key = str(ans) + key[:31]
R = format(int(R[::-1],2),'x') flag = "flag{" + R + "}" print flag
以上我直接复制,很明显按他的代码存在一些对数字的逆序处理,而且mark也是倒过来的,我很难绕欸
我们看回题目
1 2 3 4
for j in range(8): (R,out)=lfsr(R,mask) tmp=(tmp << 1)^out f.write(chr(tmp))
R = '' for i in range(32): output = '?' + xlsb[:31] ans = int(tmp[-1-i])^int(output[-3])^int(output[-5])^int(output[-8])^int(output[-12])^int(output[-20])^int(output[-27])^int(output[-30]) R += str(ans) xlsb = str(ans) + xlsb[:31]
R = format(int(R[::-1],2),'x') flag = "flag{" + R + "}" print flag